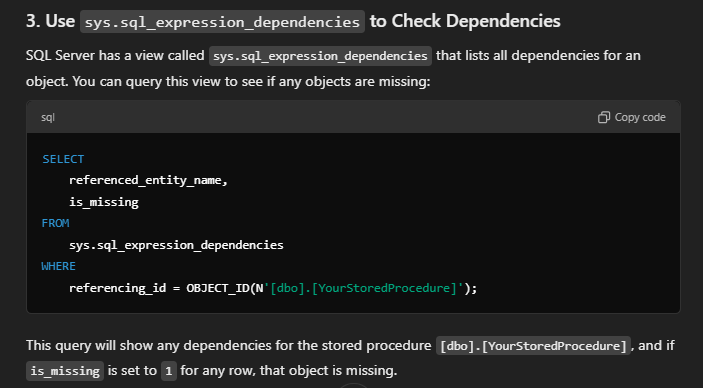
I was just wondering how does ChatGPT sometimes come up with information totally made up. In this case on well documented SQL server DMV, which is documented and there must be more correct than incorrect information on the internet – used for the learning.
in this case this was the incorrect information I was given
sys.sql_expression_depencies DOES NOT have “is_missing” column obviously, would be cool if it did, but it doesn’t.
Don’t get me wrong, I love ChatGPT and AI tools as little helpers, but makes me wonder how many people do trust it entirely and do copy paste type of work with that.
Imagine a scenario where you need to deploy your application, which contains a significant amount of valuable know-how, to a SQL server that is not under your control or is managed by other DBAs. In most cases, you are deploying your application to a customer, and naturally, you want to protect your intellectual property (IP). Is there a way to achieve this? The short answer is no, there isn’t. While there may be some security measures in place, I firmly believe that there is no foolproof method to safeguard data from users with sysadmin access and server admin access. Just a note, Always Encrypted was not a solution in our case, although considered.
So, how did I approach this problem? I decided to add additional layers of security to minimize the risk of unauthorized access to sensitive data.
On the SQL server itself, I created a symmetric key using a password to encrypt the data. The next question was where to store the password required to open the symmetric key. One obvious option was to embed it in a stored procedure and encrypt the stored procedure itself. Even sysadmins do not have the ability to alter encrypted stored procedures from SQL Server Management Studio (SSMS). However, they can potentially use free third-party tools to decrypt the stored procedure and retrieve the original code. This taught me that stored procedure encryption, while helpful, is not entirely foolproof.
Since my application relies on SQL data, another option was to embed the data directly into the application and compile it. This might seem like a bulletproof solution, as the code would be in binary form, making it unreadable. However, in reality, it’s relatively easy to decompile, for instance, C# code using free tools. Reverse engineering has become more accessible than it used to be.
In the end, the level of security you can achieve depends on various factors. If possible, dividing your solution and not centralizing everything can be beneficial. While you might encounter a curious DBA, they typically lack the development experience required to easily access your application code. You can also consider obtaining sensitive data from external resources and storing them only in the memory of the running application or in temporary objects within the SQL server. However, as mentioned earlier, it’s challenging to guarantee that someone won’t hijack your process and access and save the data elsewhere. Ultimately, the level of protection you need depends on the value of your data and whether others can make use of it without understanding its context.
This post about SQL server extended events was written based on the invitation 166 from scarydba.com. Still not sure why I haven’t noticed the invitation on the official web of tsqltuesday.com but found it by #tsql2sday
They have been around since SQL 2012, what has changed? Microsoft have done some enhancements to the impact on performance, they added new events, but what has not changed is the user unfriendliness. I feel this is the biggest downside of extended events, especially the need to process results from XML.
There has been 0 development in SSMS, but you have the option to use an extension for Azure data studio, which is handy and provides a similar interface to SQL profiler. Damn SQL profiler deprecated since when 2016? For how long it will be present? We know all the downsides of this tool, but wasn’t it handy at least once in our lives?
Btw. Azure data studio – why is majority DB users still using SSMS, is it a force of habit? Do they think it is only for Azure? Well, I do use SSMS more often, because it is available on instances where I am connecting, but sometimes I blame myself of being to lazy to drive the change. With this thought I found a nice article comparing features of ADS vs SSMS, feels like SSMS got a lot of point for features that are not used or at least not often used.
Another thing with extended events is that they are not always cheap and they can have an impact on the server. As a result rule no. 1 should be to set up your filters properly and be careful with predicated that can be evaluated after the event is actually collected, these won’t help to optimize collection performance.
Recently I came across a great library XESmartTarget that helps you read extended events externally and save data in a better structure than XML, e.g.: directly into DB table, there a lot of options that this library offers and we are going to use it for new features in Server Monitoring and Tuning tool (SMT).
Thank you for this topic and I look forward to reading posts of others.
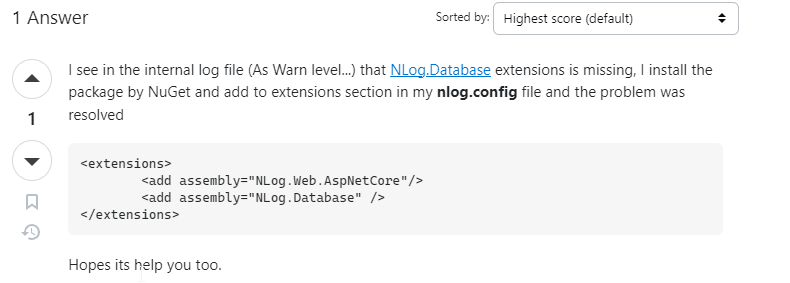
NLOG is a great framework to log errors to all kind of targets, I learned about it when I was working on including XESmartTarget into our product. There is a lot of sources to help out with initial implementation and logging to console was straight forward, the problem started when I wanted to log information into database – again found a fair bit of information online either in documentation or on blog posts, but nobody told me the following;
I was wondering why my database target was omitted and only file and console were loaded from Nlog.config file.
This worked for me. It is also worth noting that internalLogLevel needs to be set as well to track internal issues during your implementation, you can also set throwExceptions to true, although few times I just got an exit error code, in the other instances I saw an actual exceptions that was helpful.
With a rising prices of utilities like gas and power and winter still being in progress it might be good to check your usage from time to time. With electricity and TOU meters, it is easy, retailer does that for you and you can check your consumption and projected bill at any time with a granularity of 30 minute interval (sometimes even less). With gas (and water) it is trickier, those are being read manually every 2 – 3 months so you may be up for a surprise when the bill arrives.
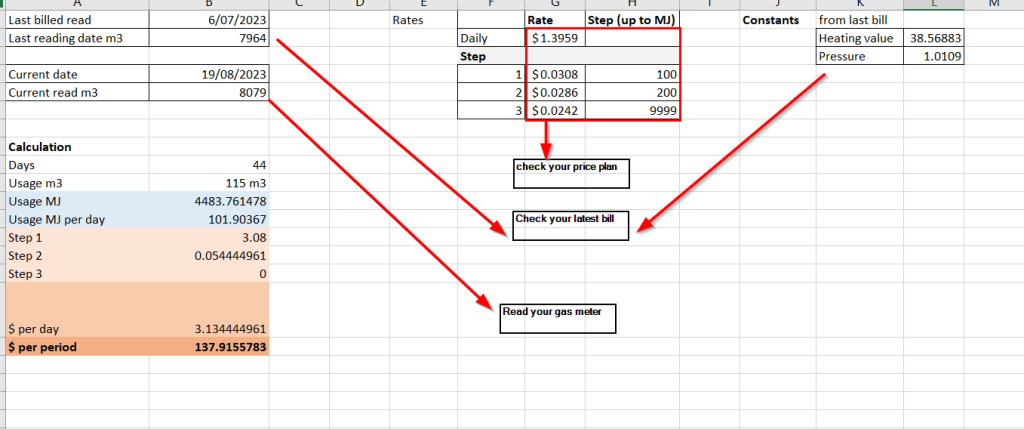
I have created a simple excel file, where you can fill your rates, dates, latest and current meter reading and it will give you amount that you would pay if the bill was issued right now.
Just open the attached excel file and fill out. Check the picture where to get the details.
Apart from obvious things like dates and readings of the meter you have to fill rates from your price plan. Usually this consists from a daily rate – what you pay no matter what is your consumption and then usage rates, which are then usually divided into steps – you pay certain rate for your first X MegaJoules, slightly different rate for another Y MJ etc. Excel supports 3 steps pricing. On top of all of that you have to fill 2 values specific for GAS, which are heating value and pressure. Simply use whatever gave you your retailer on your last bill, it will be different (shouldn’t be significant) on your next invoice, but there is no way how to figure out these by yourself.
By definition, T-SQL is not case sensitive, but there are scenarios where it can exhibit partial case sensitivity.
Consider a scenario where you deploy a database for your application using a Case Insensitive (CI) collation. Initially, everything works fine, even if you occasionally deviate from naming guidelines or use different casings within your code, such as in stored procedures. However, problems arise when you deploy the same database to a server with a Case Sensitive (CS) collation.
Then on another day you deploy your database to a server and you start getting weird errors, like “Invalid column” or even “Must declare the scalar variable”. That’s the point when you find out the server’s default collation is Case Sensitive (CS) and it is affecting your code, that is working within a scope of your case insensitive database.
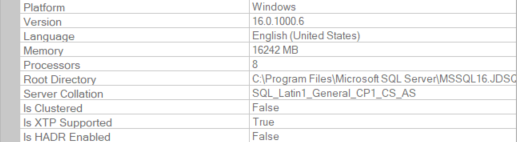
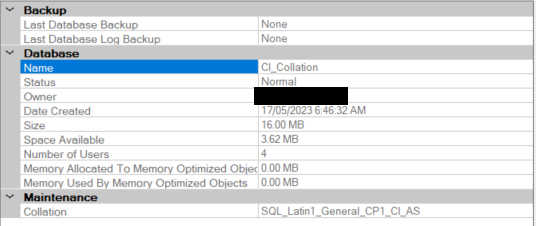
Let’s examine some examples using a SQL 2022 server with a CS collation.
Fig 1.: Server properties.
Then I have my database using CI collation.
Fig 2.: Database properties.
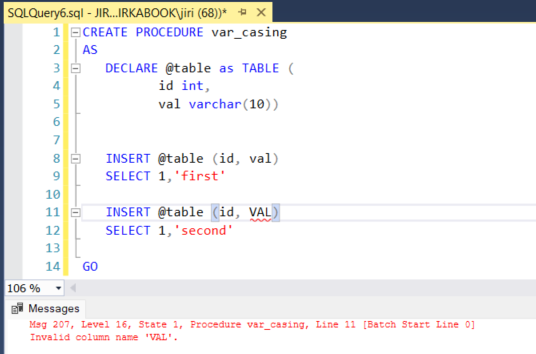
In this case, we attempt to create a procedure for our application. The situation is identical when using table variables or temporary tables.
Fig 3.: Failed procedure deployment, because of non-existent column. Invalid column error.
At first glance, you may wonder why you haven’t encountered this error before or why it worked on other servers. The answer lies in checking the collation settings of the server and system databases. As the object is created in memory, it is likely that the object declaration passes through a temporary table or another system database controlled by the CS collation. In this case, the system recognizes “@table” and column “val” but does not recognize “VAL.”
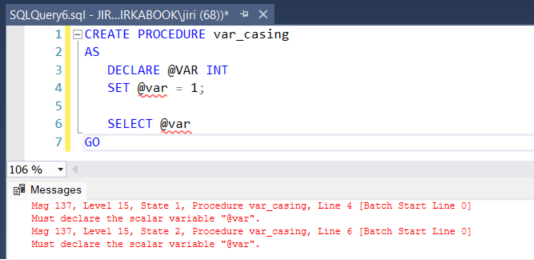
Fig 4.: Unknown variable. Must declare the scalar variable @var error.
While it is an assumption without delving into SQL Server internals, even variables likely pass through a system object with a CS collation.
Although the procedure is not compiled during creation, the parser must ensure that the code is valid. Therefore, errors are revealed during the creation stage rather than when the procedure is executed for the first time.
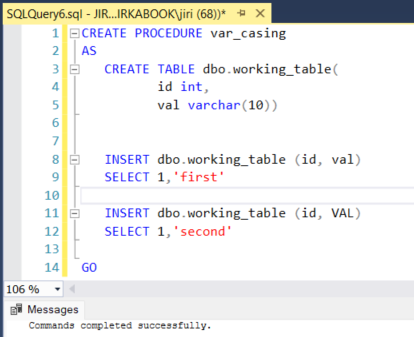
Finally, an evidence that if we are stay strictly within the scope of our database with CI collation we will be able to make it through with our “messy” code.
Fig 5.: Different casing working with physical objects
Upon further reflection, it is interesting to note that the parser does not physically create the object. To parse the code, it likely utilizes internal objects within the user database itself, which are not case sensitive. This explains why T-SQL code with inconsistent casing can still function within the scope of a case-insensitive database.
In conclusion, while T-SQL is generally not case sensitive, its behavior can be influenced by the collation settings of the server and system databases. When deploying a case-insensitive database to a case-sensitive server, unexpected errors related to object and variable names may arise. Therefore, it is important to consider collation settings and potential case sensitivity issues when working with T-SQL code.
How can you enforce casing during your development process? Finding an ideal solution can be challenging. In Visual Studio SSDT (SQL Server Data Tools), you have the option to set the database to a case-sensitive collation. However, it’s important to note that deploying your project with this collation will require adjustments during the publishing phase if you intend to maintain the original collation. It’s worth mentioning that this change applies to the user database and not the system, which means that altering the collation of reference databases like master or tempdb poses a challenge. In this situation, it is recommended to have a dedicated development or UAT (User Acceptance Testing) environment that utilizes a case-sensitive collation setup. This allows you to catch any errors related to case sensitivity during the development stage. Additionally, SQL Prompt from Redgate offers a feature to apply casing at the script level, but a method to apply it to an entire project or solution has not been found yet.
Did you know that you can change the server collation if it shows the one chosen during installation is not the ideal one?
You can also change the collation of your database. While changing the database collation may seem like a simpler process, it’s important to note that it does not automatically update existing objects and data. Therefore, changing the database collation can be a complex and potentially time-consuming endeavour.
My favourite SQL 2022 feature? Just from introductions and blogposts I really look forward to PSP (not a gaming console) and in general Query store changes to help optimize queries. It sounds like Microsoft got the confidence about Query store to enable it by default, which will definitely force more DBAs to keep it enabled and hopefully to use it as I feel that among DBAs it is still not a staple tool or feature.
Especially with Parameter Sensitive Plan optimization, it will be interesting how is it going to work in real life among different systems and workloads, but for sure a step forward.
On top of that as a T-SQL developer I look forward to changes in TSQL itself, although to be fair, some of them just follow the ANSI standard, so it is not like Microsoft came up with everything on their own.
The thing with new features makes me wonder how hard would it be to get them into older and still supported versions and if Microsoft actually wants to do that. I understand that the SQL version has to be upgraded (and a new licence paid) at the end of the lifecycle, although how much support from Microsoft itself you have ever gotten? Getting new features to supported versions would make changes to the community of SQL server so much faster, just imagine that as a dev working on a product, that has to wait on all supported versions you have to wait a few years until the 20222 version will be the oldest supported and then you can start using new T-SQL commands otherwise your code would not work on older versions.
I understand it’s not easy and it is not just adding a new T-SQL command/function into CU and that the changes are happening across the product – like it is not just the interpreter but also the query optimizer etc. I am just saying that this is keeping the process of adopting new features quite slow. On the other hand, does not Microsoft like this, we know that the development especially with big additions like Columnstore indexes, Query store etc. is gradual and stretches over a few versions maybe it is just for good that only those how are really keen and have the option start using everything once it is released, Microsoft could get relevant feedback from all the “testers” and then make it steady for the rest of us.
And on the topic of new year’s resolutions? I don’t like them, I don’t do them. I believe that if you want to make a change, you should start any day a year, ideally immediately, not making drastic decisions and be consistent with small changes to your life and making the “resolutions” your new lifestyle, like eating healthy food, exercise etc. is much better and on a long time scale has a better chance for success.
Hope you liked my first T-SQL Tuesday attendance and I already look forward to #160.
Jiri D.
This blog was written based on tsqltuesday.com invitation #159
Choosing the name – I live in Australia, I love koalas, sqlkoala.com was free, so this one was sorted.
Technology – I know that these days cloud services like Wix are probably the easiest way with quite a little monthly fee. I feel like once you need anything advanced you have to upgrade your subscription. I also had some mild experience with WordPress and gives me more control about any customisation and adjustments. So it’s self-hosted WordPress.
Design – just picked a theme. I tried to create a header but was waste of time, probably do not have enough patience and also lack the artistic feeling. At the end I just used background colour and put a logo on top of it. The logo story is quite interesting – AI have created it – thanks to DALL-E 2